A Deep Dive into the Regret Bound of GP-UCB Optimization (Part II)
In the second part of this blog series (see Part I and Part III), we aim to derive the regret bound of GP-UCB optimization in an agnostic setting. We consider an arbitrary function \(f\) belongs to a reproducing kernel Hilbert space (RKHS), associated with the kernel \(k(x, x^\prime), \; \forall x \in D\).
Introduction
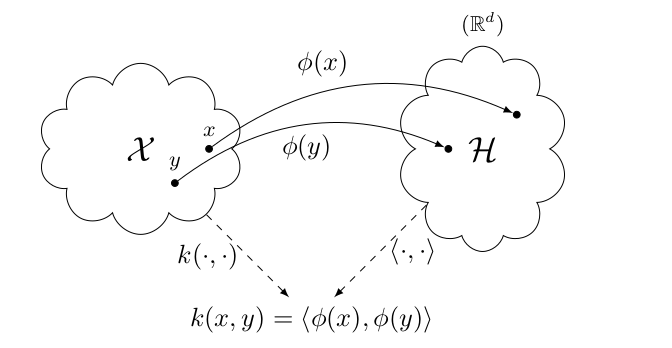
Reproducing kernel Hilbert space (RKHS). Let \(\mathcal{X}\) be a non empty set and \(k\) be a positive definite kernel on \(\mathcal{X}\). A Hilbert space \(\mathcal{H}_k\) of function on \(\mathcal{X}\) equipped with an inner product \(\langle ., . \rangle_{\mathcal{H}_k}\) is called a reproducing kernel Hilbert space (RKHS) with reproducing kernel \(k\), if the following are satisfied:
- For all \(x \in \mathcal{X}\), we have \(k(., x) \in \mathcal{H}_k\).
- For all \(x \in \mathcal{X}\), and for all \(f \in \mathcal{H}_k\)
Martingale. Martingale is a stochastic process \(X_1, \dots, X_N\) that satisfies for any time \(n\),
\[\begin{eqnarray} && \mathbb{E}[\vert X_n \vert] < \infty \nonumber \\ && \mathbb{E}[X_{n + 1} \vert X_1, \dots, X_n] = X_n \nonumber \end{eqnarray}\]that is, the condition expected value of the next observation, given all the history is determined only by the current observation.
This agnostic setting introduces key differences compared to the previous one:
- Function space: \(f\) is no longer restricted to sample drawn from a GP. Instead, it can be an arbitrary function from \(\mathcal{H}_k(D)\).
- Noise model relaxation: While UCB assumes that the noise \(\epsilon_t = y_t - f(x_t)\) is drawn independently from \(N(0, \sigma^2)\), we relax the assumption such that the sequence of noise variables can be a uniformly bounded martingale difference sequence: \(\epsilon_t \leq \sigma\) for all \(t \in \mathbb{N}\).
Regret Bound for the Function in RKHS
Theorem 3 Let \(\delta \in (0, 1)\). Assume that the true underflying \(f\) lies in RKHS \(\mathcal{H}_k(D)\) corresponding to the kernel \(k(x, x^\prime)\) and the noise \(\epsilon_t\) has zero mean conditioned on the history and is bounded by \(\sigma\) almost surely. In particular, assume \(\Vert f \Vert_k^2 \leq B\) and let \(\beta_t = 2B + 300 \gamma_t \log^3 (t / \delta)\). Running GP-UCB with \(\beta_t\), prior \(GP(0, k(x, x^\prime))\) and noise model \(N(0, \sigma^2)\), we obtain a regret bound of \(\mathcal{O}(\sqrt{T}(B \sqrt{\gamma_T} + \gamma_T))\) with high probability. Precisely,
\[\begin{equation} \mathbb{P}(R_T \leq \sqrt{C_1 T \beta_T \gamma_T} \quad \forall T \geq 1) \geq 1 - \delta \nonumber \end{equation}\]where \(C_1 = 8 / \log(1 + \sigma^{-2})\).
Proof:
Given the posterior covariance \(k_T(., .)\), we have
\[\begin{equation} \Vert f \Vert^2_{k_T} = \Vert f \Vert_k^2 + \sigma^{-2} \sum_{t = 1}^T f(x_t)^2 \nonumber \end{equation}\]It implies that \(\mathcal{H}_k(D) = \mathcal{H}_{k_T}(D)\), while \(\Vert f \Vert_{k_T} \leq \Vert f \Vert_{k}\). By the reproducing property and Cauchy-Schwarz inequality, we have
\[\begin{eqnarray} \vert \mu_t(x) - f(x) \vert &\leq& k_T(x, x)^{1 / 2} \Vert \mu_t - f \Vert_{k_T} \nonumber \\ &=& \sigma_T(x) \Vert \mu_t - f \Vert_{k_T} \label{eq:rkhs-inequality} \end{eqnarray}\]We need to lift up Theorem 1 to the agnostic setting in order to prove Theorem 3. For that purpose, it requires the following theorem to have an equivalence of Lemma 5.1 (see Part I).
Theorem 6 Let \(\delta \in (0, 1)\). Assume the noise variance \(\epsilon_t\) are uniformly bounded by \(\sigma\). Define
\[\begin{equation} \beta_t = 2 \Vert f \Vert_k^2 + 300 \gamma_t \ln^3(t / \delta), \nonumber \end{equation}\]Then
\[\begin{equation} \mathbb{P}(\forall T, \forall x \in D, \vert \mu_T(x) - f(x) \vert \leq \beta_{T + 1}^{1 / 2} \sigma_T(x)) \geq 1 - \delta \nonumber \end{equation}\]Proof:
The strategy is to show that
\[\begin{equation} \mathbb{P}\left( \forall T, \Vert \mu_T - f \Vert_{k_T} \leq \beta_{T + 1} \right) \geq 1 - \delta \nonumber \end{equation}\]Theorem 6 will follow from \eqref{eq:rkhs-inequality}. The proof analyzes the quantity \(Z_T\) and then bounds the martiangle difference.
Bound of \(Z_t\)
We first analyze the quantity \(Z_T = \Vert \mu_T - f \Vert_{k_T}^2\), that is the error of \(\mu_T\) as the approximation of \(f\) under the RKHS norm \(\mathcal{H}_{k_T}(D)\). The analysis requires a lemma which is responsible to bound the growth of \(Z_T\). Establishing this lemma requires normalized quantities: \(\tilde{\epsilon}_t = \epsilon_t / \sigma, \tilde{f} = f / \sigma, \tilde{\mu}_t = \mu_t / \sigma, \tilde{\sigma}_t = \sigma_t / \sigma\). For convenience, \(\mu_{t - 1}\) and \(\sigma_{t - 1}\) are the shorthand for \(\mu_{t - 1}(x_t)\) and \(\sigma_{t - 1}(x_t)\), respectively.
Lemma 7.2 For all \(T \in \mathbb{N}\),
\[\begin{equation} Z_T \leq \Vert f \Vert^2_k + 2 \sum_{t = 1}^T \tilde{\varepsilon}_t \frac{\tilde{\mu}_{t - 1} - \tilde{f}(x_t)}{1 + \tilde{\sigma}_{t - 1}^2} + \sum_{t = 1}^T \tilde{\varepsilon}^2_t \frac{\tilde{\sigma}_{t - 1}}{1 + \tilde{\sigma}_{t - 1}^2} \nonumber \end{equation}\]Proof:
If \(\boldsymbol{\alpha}_t = (\mathbf{K}_t + \sigma^2 \mathbf{I})^{-1} \mathbf{y}_t\), then \(\mu_t(x) = \boldsymbol{\alpha}_t^\top \mathbf{k}_t(x)\). Moreover, we have \(\langle \mu_T, f \rangle_k = \mathbf{f}^\top_T \boldsymbol{\alpha}_T, \Vert \mu_T \Vert^2_k = \mathbf{y}_T^\top \boldsymbol{\alpha}_T - \sigma^2 \Vert \boldsymbol{\alpha}_T \Vert^2, \mu_T(x_t) = \boldsymbol{\delta}_t^\top \mathbf{K}_T (\mathbf{K}_T + \sigma^2 \mathbf{I})^{-1} \mathbf{y}_T = y_t - \sigma^2 \alpha_t\). Since \(Z_T = \Vert \mu_T - f \Vert_k + \sigma^{-2} \sum_{t \leq T} (\mu_T(x_t) - f(x_t))^2\), we have
\[\begin{eqnarray} Z_T &&= \Vert f \Vert_k^2 - 2 \mathbf{f}_T^\top \boldsymbol{\alpha}_T + \mathbf{y}_T^\top \boldsymbol{\alpha}_T - \sigma^2 \Vert \alpha_T \Vert^2 + \sigma^{-2} \sum_{t = 1}^T (\epsilon_t - \sigma^2 \alpha_t)^2 \nonumber \\ && = \Vert f \Vert_k^2 - \mathbf{y}_T^\top (\mathbf{K}_T + \sigma^2 \mathbf{I})^{-1} \mathbf{y}_T + \sigma^{-2} \Vert \boldsymbol{\epsilon}_T \Vert^2 \nonumber \end{eqnarray}\]Note that \(2 \log p(\mathbf{y}_t) \propto - \mathbf{y}_T^\top (\mathbf{K}_T + \sigma^2 \mathbf{I})^{-1} \mathbf{y}_T\). Since \(\log p(\mathbf{y}_T) = \sum_{t = 1} \log p(y_t \vert \mathbf{y}_{< t}) = \sum_t \log N(y_t \vert \mu_{t - 1}(x_t), \sigma^2_{t - 1}(x_t) + \sigma^2)\), we have
\[\begin{eqnarray} &&- \mathbf{y}_T^\top (\mathbf{K}_T + \sigma^2 \mathbf{I})^{-1} \mathbf{y}_T = - \sum_t \frac{(y_t - \mu_{t - 1})^2}{\sigma^2 + \sigma_{t - 1}^2} \nonumber \\ && = 2 \sum_t \epsilon_t \frac{\mu_{t - 1} - f(x_t)}{\sigma^2 + \sigma^2_{t - 1}} - \sum_t \frac{\epsilon_t^2 \tilde{\sigma}^2_{t - 1}}{\sigma^2 + \sigma^2_{t - 1}} - R \nonumber \end{eqnarray}\]with \(R = \sum_t (\mu_{t - 1} - f(x_t))^2 / (\sigma^2 + \sigma^2_{t - 1}) \geq 0\). Dropping \(-R\) and changing to normalized quantities concludes the proof.
Concentration of Martingale
We need the following lemma to construct the proof of Lemma 7.3.
Lemma 7.1 We have that
\[\begin{equation} \sum_{t = 1}^T \min(\sigma^{-2} \sigma^2_{t - 1}(x_t), \alpha) \leq \frac{2 \alpha}{\log (1 + \alpha) \gamma_T}, \quad \alpha > 0 \nonumber \end{equation}\]Proof:
We have that \(\min(r, \alpha) \leq (\alpha / \log(1 + \alpha)) \log (1 + r)\). The statement follows from Lemma 5.3. (see Part I)
We also need the concentration inequality for martingale differences:
Theorem 7 (Freedman) Suppose \(X_1, \dots, X_T\) is a martingale difference sequence, and \(b\) is an uniform upper bound on the steps \(X_i\). Let \(V\) denote the sum of conditional variances,
\[\begin{equation} V = \sum_{i = 1}^n \mathbb{V}[X_i \vert X_1, \dots, X_{i - 1}] \nonumber \end{equation}\]Then, for every \(a, v > 0\),
\[\begin{equation} \mathbb{P}\left(\sum X_i \leq a \, \text{and} \, V \leq v \right) \leq \exp\left( \frac{- a^2}{2v + 2ab / 3} \right) \nonumber \end{equation}\]We now define a martingale difference sequence. First, we define the “escape-event” \(E_T\) as
\[\begin{equation} E_T = I\{ Z_t \leq \beta_{t + 1} \; \text{for all} \; t \leq T \} \nonumber \end{equation}\]Subsequently, we define the random variables \(M_t\) by
\[\begin{equation} M_t = 2 \tilde{\epsilon_t} E_{t - 1} \frac{\tilde{\mu}_{t -1 } - \tilde{f}(x_t)}{1 + \tilde{\sigma}^2_{t - 1}} \nonumber \end{equation}\]Remark: Since \(\tilde{\epsilon}_t\) is a martingale difference sequence w.r.t. the histories and \(M_t / \tilde{\epsilon}_t\) is deterministic given the history, \(M_t\) is martingale difference sequence as well.
The following lemma tells with a high probability, the associated martingale \(\sum_{t = 1}^T M_t\) does not grow too large.
Lemma 7.3 Given \(\delta \in (0, 1)\) and \(\beta_t\) as defined in Theorem 6, we have that
\[\begin{equation} \mathbb{P} \left(\forall T, \sum_{t = 1}^T M_t \leq \beta_{T + 1} / 2 \right) \geq 1 - \delta \nonumber \end{equation}\]Proof:
We first obtain upper bound on the step sizes of the martingale.
\[\begin{eqnarray} \vert M_t \vert &&= 2 \vert \tilde{\epsilon}_t \vert E_{t - 1} \frac{\vert \tilde{\mu}_{t - 1} - \tilde{f}(x_t) \vert}{1 + \tilde{\sigma}^2_{t - 1}} \nonumber \\ &&\leq 2 \vert \tilde{\epsilon}_t \vert E_{t - 1} \frac{\beta_t^{1 / 2} \tilde{\sigma}_{t - 1}}{1 + \tilde{\sigma}^2_{t - 1}} \nonumber \\ &&\leq 2 \vert \tilde{\epsilon}_t \vert E_{t - 1} \beta_{t}^{1 / 2} \min\{ \tilde{\sigma}_{t - 1}, 1 / 2 \} \nonumber \end{eqnarray}\]The first inequality follows from \eqref{eq:rkhs-inequality} and the definition of \(E_t\). The second inequality follows from the fact that \(r / (1 + r^2) \leq \min\{r, 1/2 \}\) for \(r \geq 0\). Thus, \(\vert M_t\vert \leq \beta_{T}^{1 / 2}\) since \(\vert \tilde{\epsilon} \vert \leq 1\) and \(\beta_t\) is non-decreasing. Next, we bound the sum of the conditional variances of the martingale:
\[\begin{eqnarray} V_T &&= \sum_{t = 1}^T \mathbb{V}[M_t \vert M_1, \dots, M_{t - 1}] \nonumber \\ &&\leq \sum_{t = 1}^T 4 \vert \epsilon_t \vert^2 E_{t - 1} \beta_t \min\{ \tilde{\sigma}^2_{t - 1}, 1/4 \} \nonumber \\ &&\leq 4 \beta_T \sum_{t = 1}^T E_{t - 1} \min\{\tilde{\sigma}^2_{t - 1}, 1/4 \} & \vert \tilde{\epsilon_t} \vert \leq 1 \nonumber \\ &&\leq 9 \beta_T \gamma_T \nonumber \end{eqnarray}\]The last inequality follows from Lemma 7.1, with \(\alpha=1/4\). We then apply Theorem 7 with parameters \(a = \beta_{T + 1} / 2, b = \beta_{T + 1}^{1 / 2}\), and \(v = 9 \beta_T \gamma_T\) to obtain
\[\begin{eqnarray} &&\mathbb{P}\left( \sum_{t = 1}^T M_t \geq \beta_{T + 1} / 2 \right) \nonumber \\ && = \mathbb{P}\left( \sum_{t = 1}^T M_t \geq \beta_{T + 1} / 2 \; \text{and} \; V_T \leq 9 \beta_T \gamma_T \right) \nonumber \\ && \leq \exp\left( \frac{- (\beta_{T + 1} / 2)^2 }{2 (9 \beta_T \gamma_T) + 2/3 (\beta_{T + 1} / 2) \beta_{T + 1}^{1 / 2} } \right) \nonumber \\ &&= \exp\left( \frac{- \beta_{T + 1}}{72 \gamma_T + 4/3 \beta_{T + 1}^{1 / 2}} \right) \nonumber \\ && \leq \max\left \{ \exp\left( \frac{- \beta_{T + 1}}{144 \gamma_T} \right), \exp\left( \frac{-3 \beta_{T + 1}^{1 / 2}}{8} \right) \right \} \nonumber \end{eqnarray}\]Note that \(\beta_{T + 1}\) satisfies
\[\begin{equation} \max\{ 144 \gamma_T \log (T^2 / \delta), ((8 / 3) \log (T^2 / \delta))^2 \} \leq \beta_{T + 1} \nonumber \\ \end{equation}\]Therefore, the previous probability is bounded by \(\delta / T^2\). By applying the union bound we obtain
\[\begin{eqnarray} &&\mathbb{P}\left( \sum_{t = 1}^T M_t \geq \beta_{T + 1} / 2 \quad \text{for some} \, T \right) \nonumber \\ &&\leq \sum_{T \geq 1} \mathbb{P}(\sum_{t = 1}^T M_t \geq \beta_{T + 1} / 2) \nonumber \\ &&\leq \sum_{T \geq 2} \delta / T^2 \leq \delta(\pi^2 / 6 - 1) \leq \delta \nonumber \end{eqnarray}\]completing the proof of Lemma 7.3.
[Proof of Theorem 6] By Lemma 7.2 and the definition of \(\beta_1\), we have \(Z_0 \leq \Vert f \Vert_k \leq \beta_1\). Hence, we always have \(E_0 = 1\). Suppose with a high-probability Lemma 7.3 holds, i.e., \(\sum_t M_t \leq \beta_{T + 1} / 2\). For the inductive hypothesis, assume \(E_T = 1\). By applying Lemma 7.2 we obtain
\[\begin{eqnarray} Z_T &&\leq \Vert f \Vert_k^2 + 2 \sum_{t = 1}^T \frac{\tilde{\epsilon}_t ( \tilde{\mu}_{t - 1} - \tilde{f}(x_t) )}{1 + \tilde{\sigma}^2_{t - 1}} + \sum_{t = 1}^T \frac{\tilde{\epsilon}_t^2 \tilde{\sigma}^2_{t - 1}}{1 + \tilde{\sigma}^2_{t - 1}} \nonumber \\ &&= \Vert f \Vert_k^2 + \sum_{t = 1}^T M_t + \sum_{t = 1}^T \tilde{\epsilon}_t \frac{\tilde{\sigma}^2_{t - 1}}{1 + \tilde{\sigma}^2_{t - 1}} \nonumber \\ && \leq \Vert f \Vert_k^2 + \beta_{T + 1} / 2 + \sum_{t = 1}^T \min\{\tilde{\sigma}^2_{t - 1}, 1 \} \nonumber \\ && \leq \Vert f \Vert_k^2 + \beta_{T + 1} / 2 + (2 / \log 2) \gamma_T \leq \beta_{T + 1} \nonumber \end{eqnarray}\]The equality in the second step uses the inductive hypothesis. Thus we have shown \(E_T = 1\), completing the induction.
Following the proof of Theorem 1 and replacing Lemma 5.1 with Theorem 6 leads to the results in Theorem 3. Note that Theorem 3 holds uniformly over all functions \(f\), with \(\Vert f \Vert < \infty\).
In the last part of this blog series, we aim to obtain the bound the quantity \(\gamma_T\) for practical classes of kernels.
Reference
- Srinivas, N., Krause, A., Kakade, S. M., & Seeger, M. (2009). Gaussian process optimization in the bandit setting: No regret and experimental design. arXiv preprint arXiv:0912.3995.